|
Getting your Trinity Audio player ready...
|

Realistic audio is a process that requires modeling information that is represented in different sizes. For example, just like music creates complex musical phrases by combining single notes, speech incorporates local temporal structures, like phonemes or syllables, to form sentences and words. Making well-structured and coherent audio sequences across all the scales of speech is a challenge that has been tackled by combining audio with transcripts that aid in the generative process, whether it is transcripts of speech synthesizing or the MIDI representations of the piano. But, this approach needs to be revised when it comes to modeling untranscribed audio elements, such as the characteristics of speakers essential to aid people suffering from speech difficulties in recovering their voice, as well as the stylistic aspects of a performance by a pianist.
In the paper ” AudioLM: a Language Modeling Approach for Audio Generation,” We suggest an innovative framework to generate audio, which teaches to produce real-time piano and speech through listening to only audio. Music generated using AudioLM shows long-term stability (e.g., the syntax of speech or melody within music) and high fidelity, surpassing previous systems and pushing the limits of audio generation using applications for speech synthesis and computer-assisted music. As per the AI Principles, we’ve also created a model that can identify the synthetic audio produced by AudioLM.
From Text to From Text to Language Models
In the last few years, Language models trained on large text corpora have proven their remarkable generative capabilities, ranging from an open dialogue through machines that translate or logic based on common sense. They’ve also demonstrated the ability to model messages other than text and natural pictures. The main idea of AudioLM is to make use of these advancements in language modeling to create audio that is not based on data annotations.
But, some issues must be overcome when transitioning from text models to models of audio language. One must deal with the reality that rate of data for audio is considerably more significant, which results in more lengthy sequences; even though a sentence written could be represented as just a few dozen characters, the audio waveform usually includes many thousands of variables. Additionally, there is a one-to-many connection between audio and text. That means the exact text could be interpreted by various speakers using different styles of speaking emotional content, as well as recording situations.
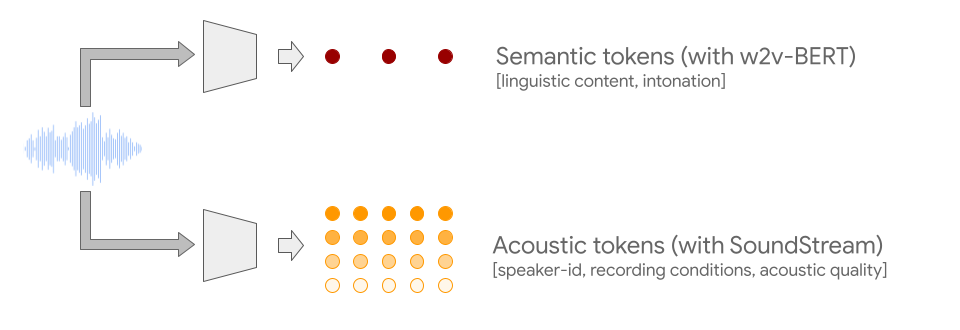
To address both issues, AudioLM leverages two kinds of audio tokens. The first is semantic tokens, which are derived from w2vBERT, which is a self-supervised audio model. These tokens can capture as well local dependency (e.g., phonetics within speech and local melodies of piano tunes) as well as lengthy global structure (e.g., the language syntax as well as semantics in the speech and harmony of the rhythm of piano music) and massively reducing the quality of the audio signal to permit modeling of long-running sequences.
But, the audio reconstructed from these tokens needs to show better fidelity. To overcome this issue and in addition to the semantic tokens, we also rely on audio tokens created by the SoundStream neural codec that capture the particulars of the sound waveform (such as the characteristics of the recording or speaker) and permit high-quality synthesizing. A system trained to create acoustic and semantic tokens results in excellent audio quality and long-term stability.
The training of an audio-only language model
AudioLM is an audio model that has been taught without any symbols or texts that represent music. AudioLM hierarchically simulates the audio sequence from semantic tokens to fine acoustic ones by chaining several transformer models with one model per stage. The stage used for training to make the following prediction of tokens using tokens from the past is similar to how one trains an existing model for text. The initial stage performs this task based on semantic tokens, which simulate the structure at the top of the sound sequence.

In the next stage, in the second stage, we combine the entire semantic token sequence with the previous coarse acoustic-based tokens and feed them both as conditioning to the coarse model, which predicts future tokens. This stage models acoustic properties such as the speaker’s characteristics, such as timbre or speech in music.

In the final phase, we combine the coarse acoustic tokens with the acceptable acoustic model, which adds even more depth to the finished audio. Then, we feed the audio tokens into the SoundStream decoder, which reconstructs the waveform.
After a training session, one can condition AudioLM to run only a few seconds of sound, and it will be able to provide consistent and continuous continuation. To illustrate the universal potential of this AudioLM system, we examine two different tasks in the audio domains:
- Speech continuation, in which models are expected to preserve the characteristics of the speaker, prosody and recording parameters of the prompt while creating the new material that’s syntactically correct and semantically coherent.
- Piano continuation, in which the model expects to create musical notes that are in sync with the prompt in terms of harmony, melody, and rhythm.
In the video above, you’ll be able to watch some examples in which the model is required to keep playing with either music or speech and create new content that was not previously seen during the training. When you listen, remember that all the audio you hear after AudioLM created the vertical gray line, and it is clear that the model hasn’t had any experience with text or musical transcription; instead, it learned from the raw audio. We will release additional samples on this page.
To confirm our findings, we asked humans to listen to a few audio clips and determine if it was an original recording of human speech or an artificial continuation created by AudioLM. Based on the evaluations we collected, we recorded a 51.2 percent success rate, which isn’t statistically significantly different from the 50 percent success rate by assigning labels randomly. This implies that the speech generated by AudioLM is challenging to differentiate from actual speech for the average user.
Our work on AudioLM is intended for research purposes only, and we do not have plans to make it public at the moment. In line with the AI Principles, we set out to discover and reduce the risk that users could mistake the speech samples that AudioLM synthesizes for genuine speech. In this regard, we developed an audio classifier that could discern synthetic speech created by AudioLM with high accuracy (98.6 percent). This indicates that, although they’re (almost) impossible to distinguish from some listeners, the continuations produced by AudioLM are extremely easily detected using an audio classifier that is simple. This is an essential first step in protecting against the misuse potential of AudioLM and possibly looking into technologies like Audio “watermarking.”
Conclusion
We present AudioLM, a language modeling method of audio generation that can provide both long-term consistency and superior audio quality. Studies on speech generation demonstrate that AudioLM can produce syntactically and semantically coherent speech with no text and that the continuations created from the modeling are identical to natural speech produced that humans use. AudioLM also goes well beyond speech and can be used to model any audio signals, such as piano music. This will allow future extensions to other audio types (e.g., polyphonic and multilingual speech or audio event) and the integration of AudioLM as an encoder-decoder framework to perform task-specific tasks such as text-to-speech or speech-to-speech transcription.
Source:- https://ai.googleblog.com/2022/10/audiolm-language-modeling-approach-to.html



